

Biography
I am currently a senior researcher at Kling Team, where I am working on the task of generative model and AIGC.
Before that, I worked at MEGVII as a researcher (2023-2025) and led a group to work on 3D reconstruction and generative models for autonomous driving. I got my master's degree and bachelor's degree at Tsinghua University (2020-2023) and Beihang University (2016-2020).
If you are interested in working with me, please contact me at dingyikang23@gmail.com, or you can add me on WeChat: yeecon_
Latest News
Feb 2026
We release the Tech Report of Kling-MotionControl, try it on Kling AI page! One paper (ORV) is accepted to CVPR 2026.
Dec 2025
Our powerful KlingAvatar 2.0 is released! Check our Tech Report and try it on Kling AI page!
Sep 2025
We're delighted to release Kling-Avatar. Try it on Kling AI Page!
Selected Publications
(* denotes equal contribution, ✝ denotes project leader.)
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
Yikang Ding*, Jiwen Liu*, Wenyuan Zhang, Zekun Wang, Wentao Hu, Liyuan Cui, Mingming Lao, Yingchao Shao, Hui Liu, Xiaohan Li, Ming Chen, Xiaoqiang Liu, Yu-Shen Liu, Pengfei Wan
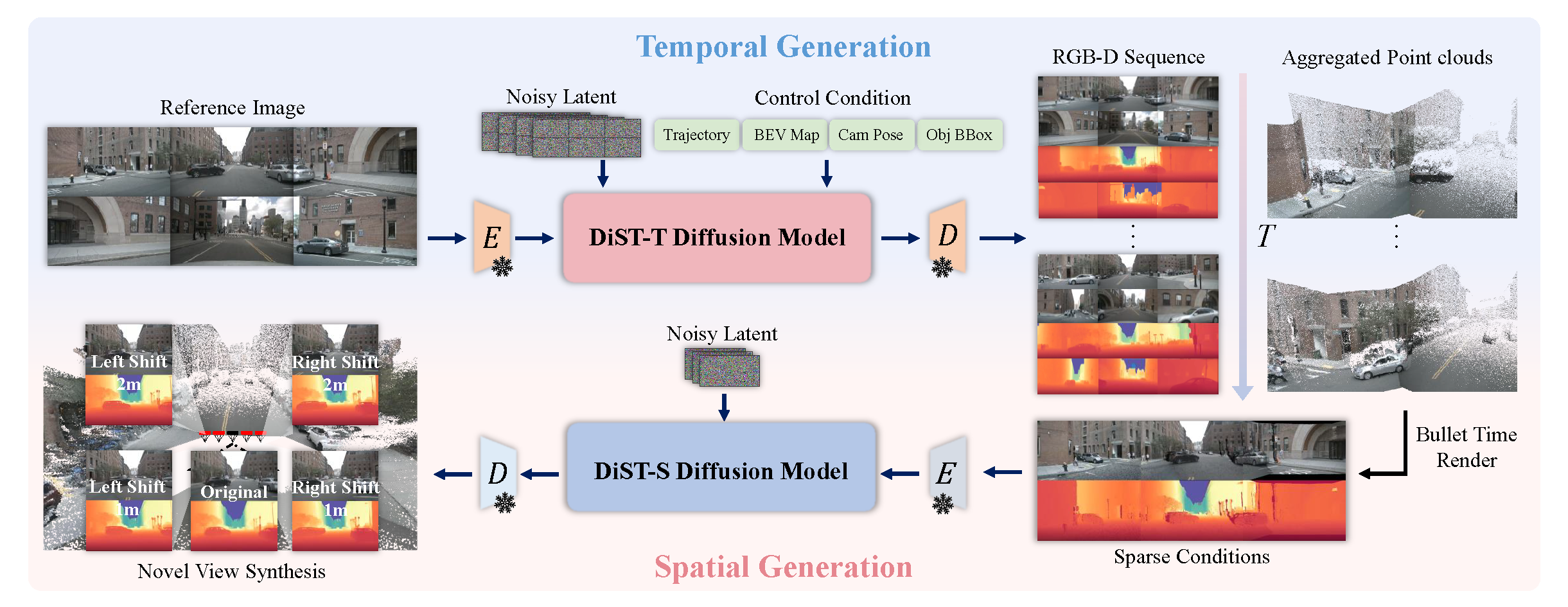
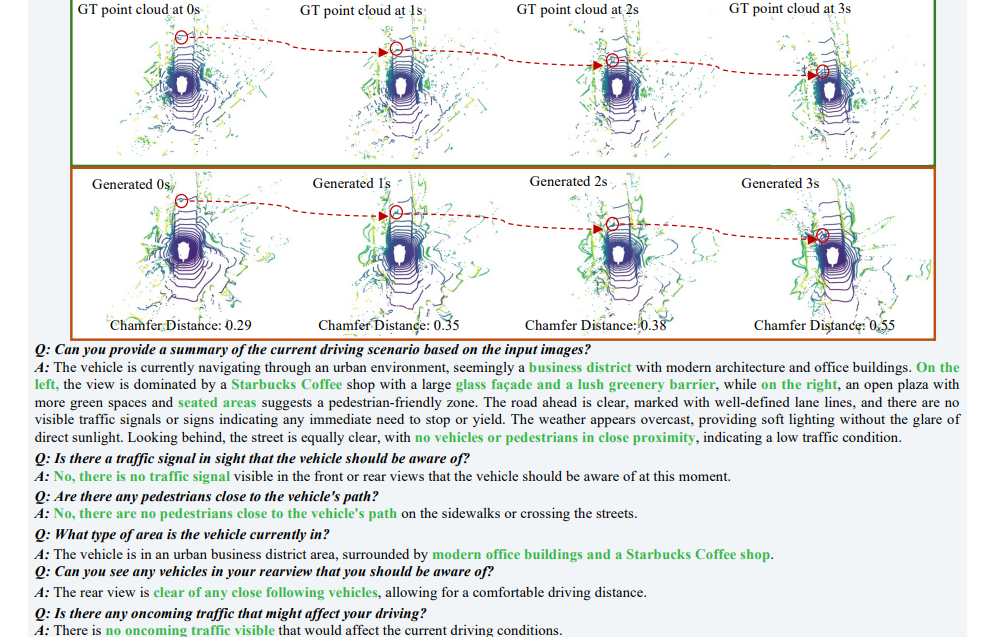
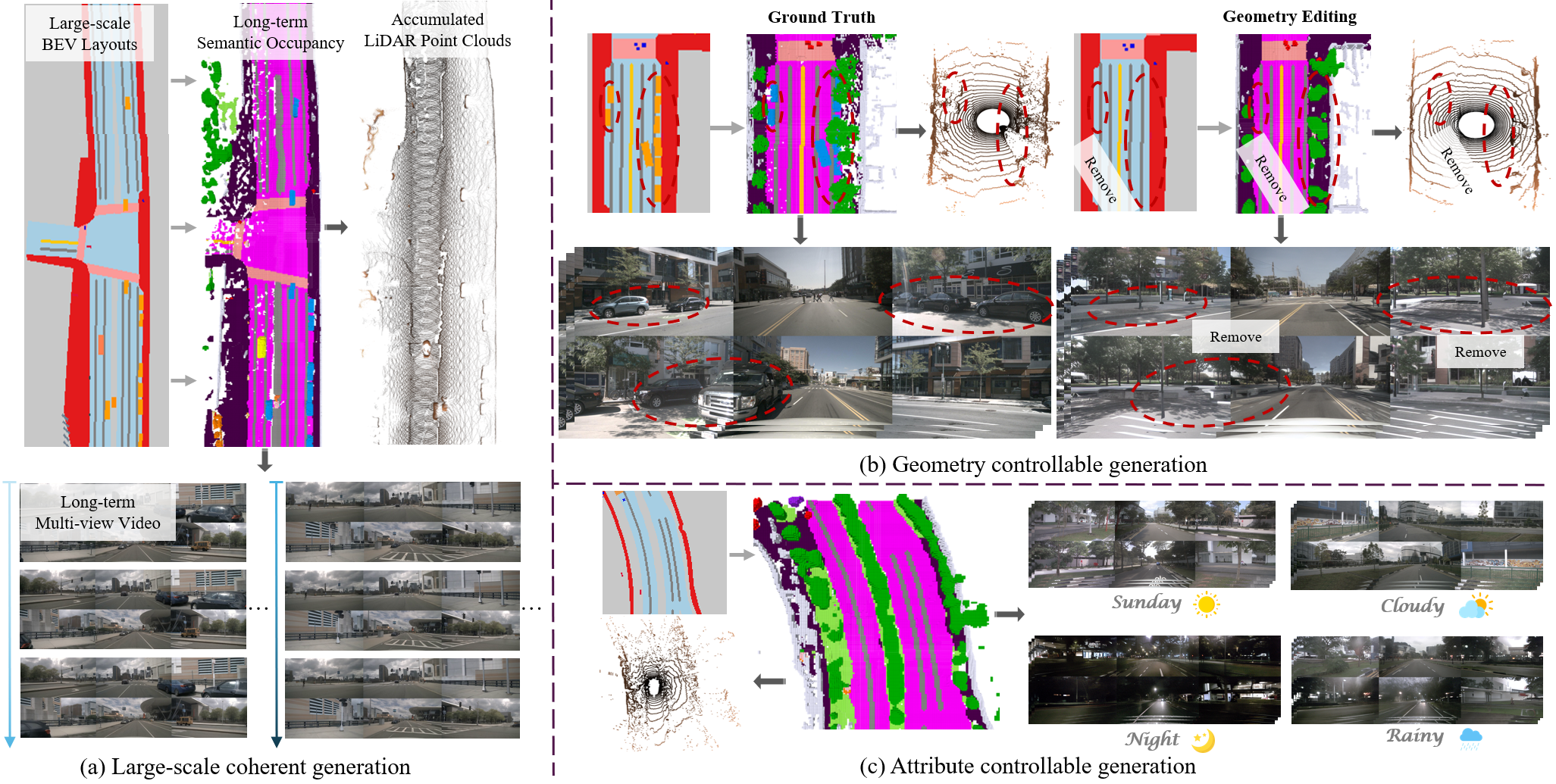
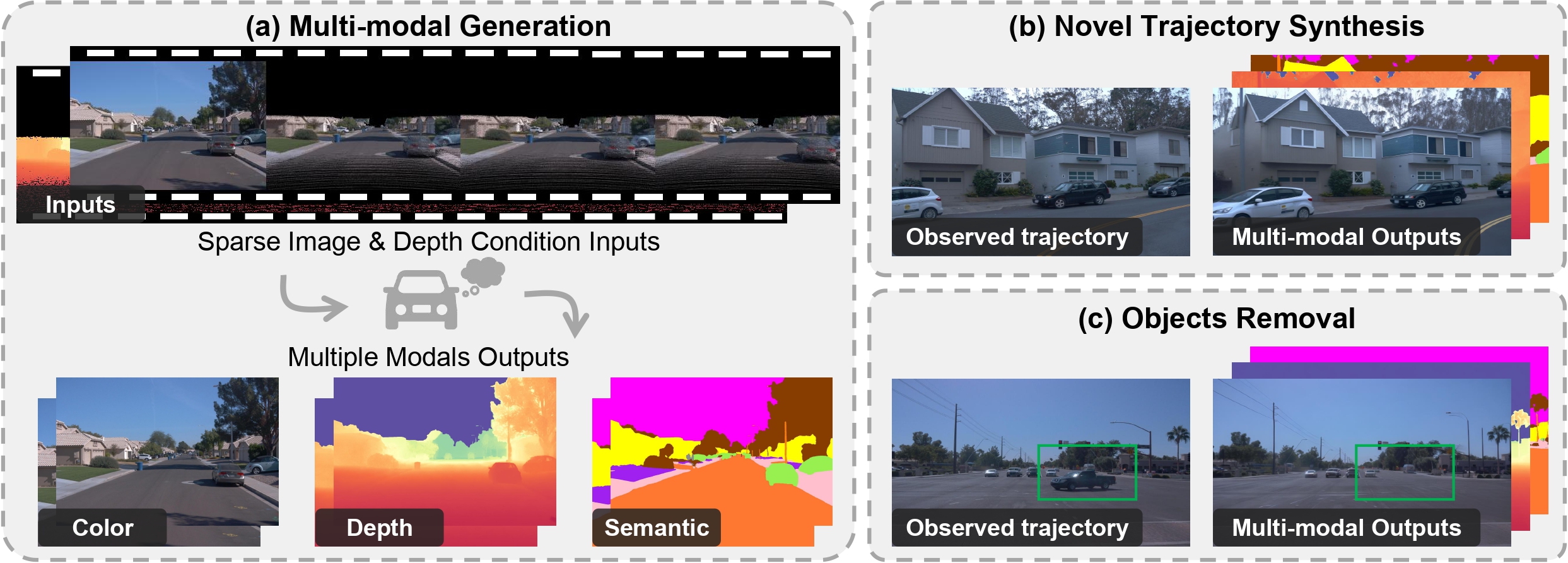

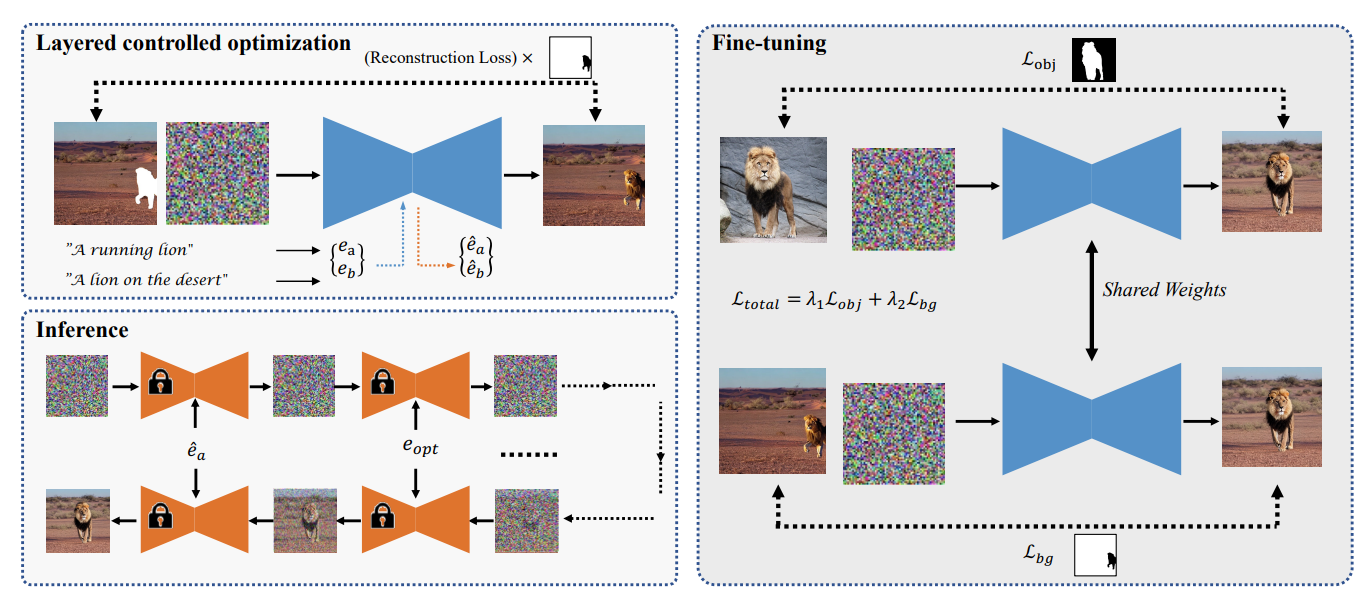
LayerDiffusion: Layered Controlled Image Editing with Diffusion Models
Pengzhi Li, Qinxuan Huang, Yikang Ding, Zhiheng Li
SIGGRAPH Asia 2023
Paper
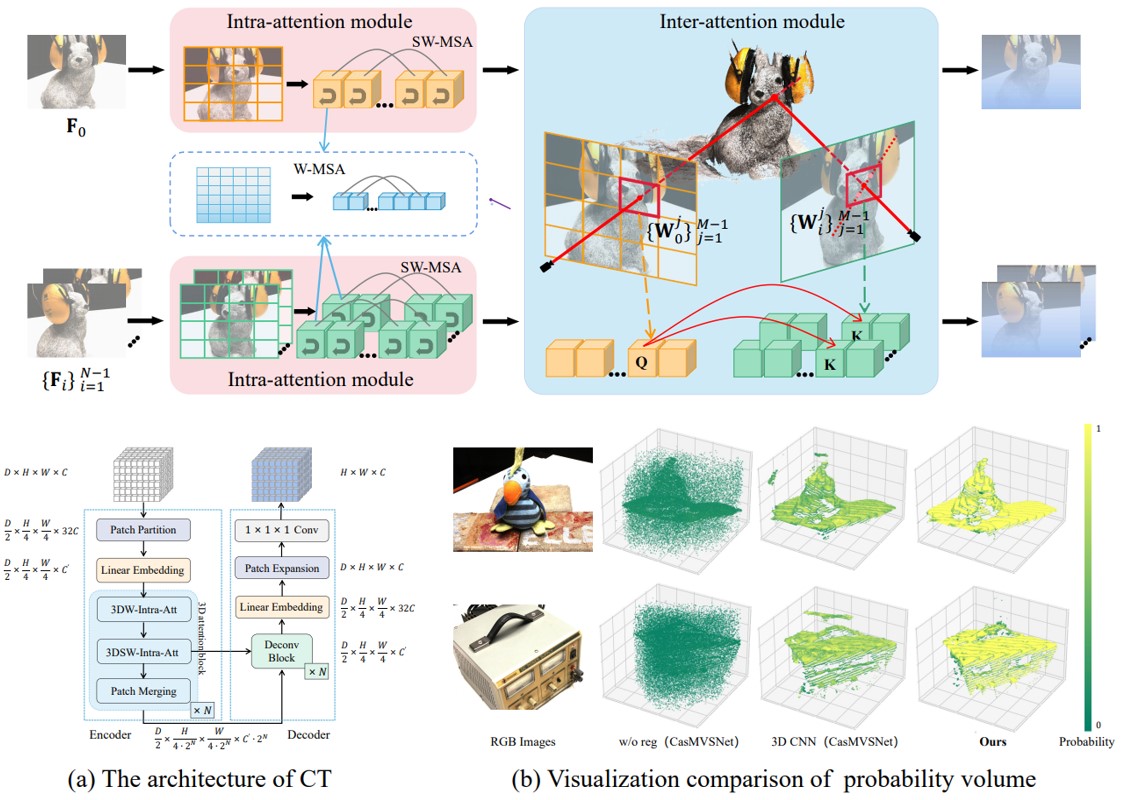
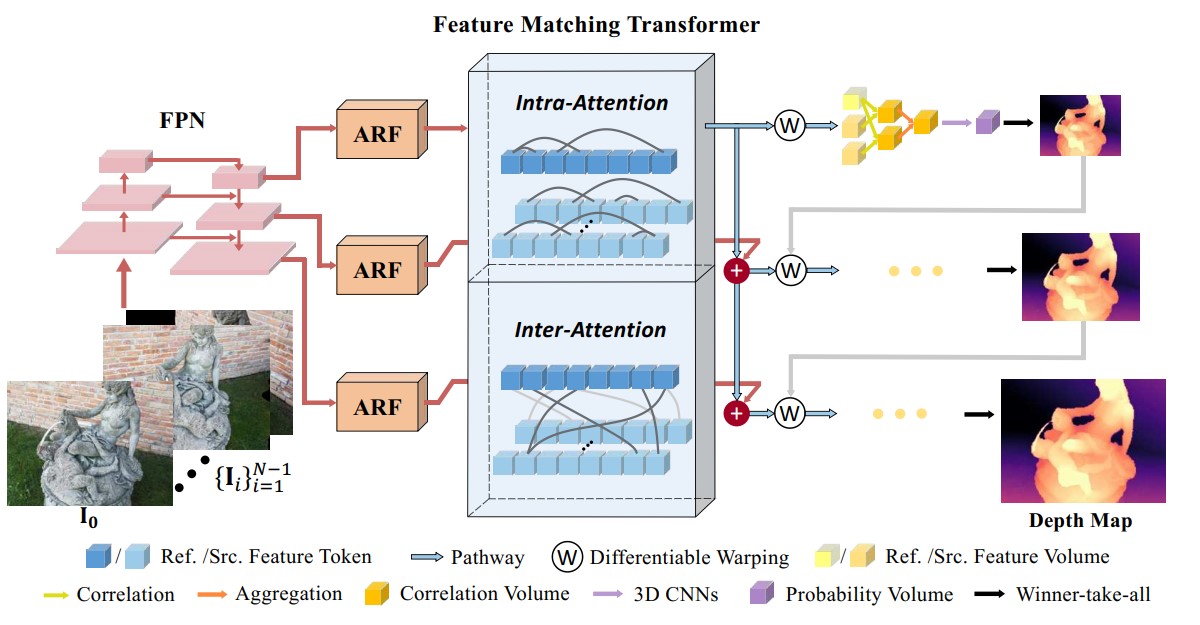
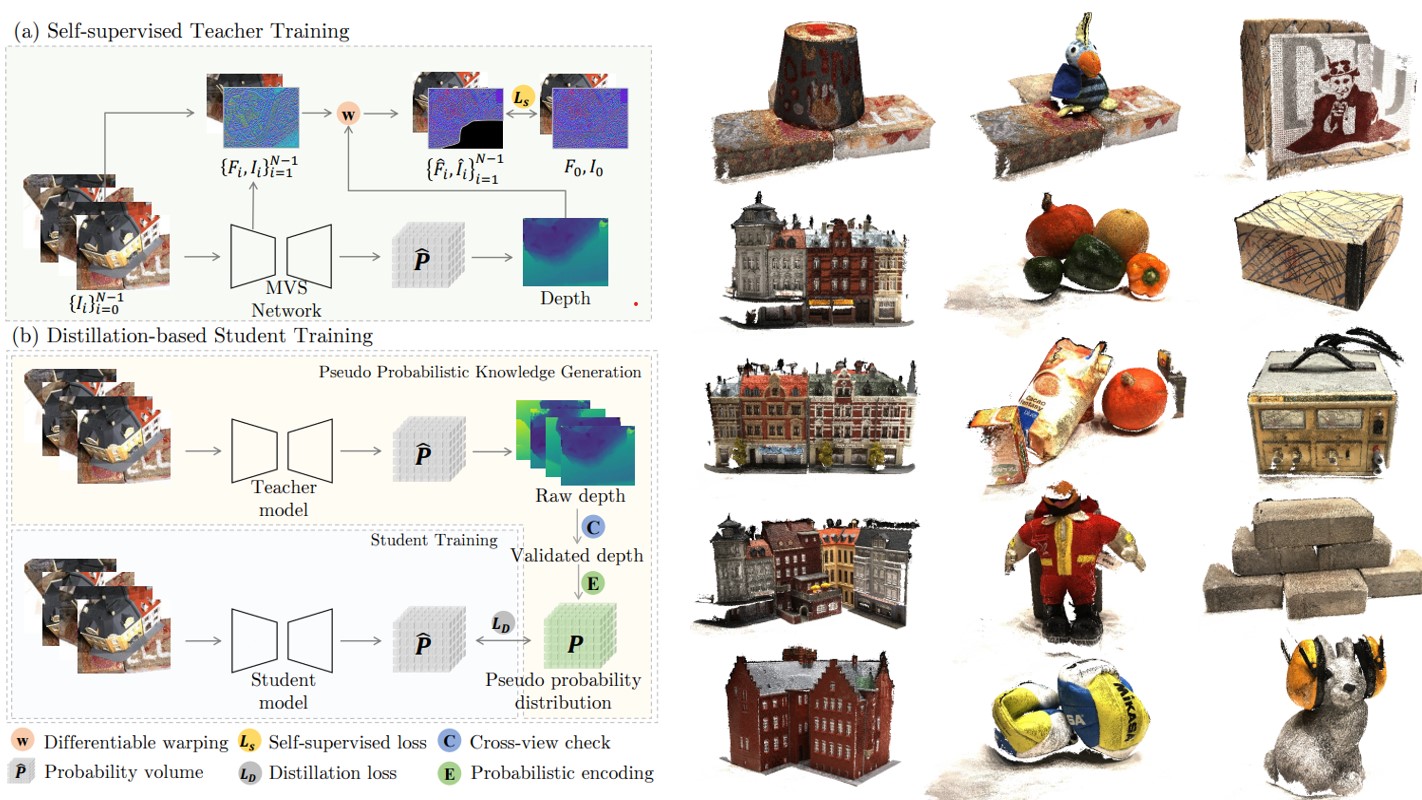
WT-MVSNet: Window-based Transformers for Multi-view Stereo
Jinli Liao*, Yikang Ding*, Yoli Shavit, Dihe Huang, Shihao Ren, Jia Guo, Wensen Feng, Kai Zhang
NeurIPS 2022
Paper
Honors & Awards
Talent Programs
- Huawei Top Talent Program (华为·天才少年计划)
- Meituan Beidou Program (美团·北斗计划)
- Li Auto Li Xiang+ Program (理想汽车·理想+计划)
- Megvii MegEagle Program (旷视·创视者计划)
Major Honors
- May Fourth Medal, Beihang University, 10 students university-wide each year. (北航·五四奖章)
- Student of the Year, Beihang University, 10 students university-wide each year. (北航·大学生年度人物)
- Outstanding Graduate of Beijing
Research Interests
3D Reconstruction
Multi-view stereo, depth estimation, scene reconstruction
World Models
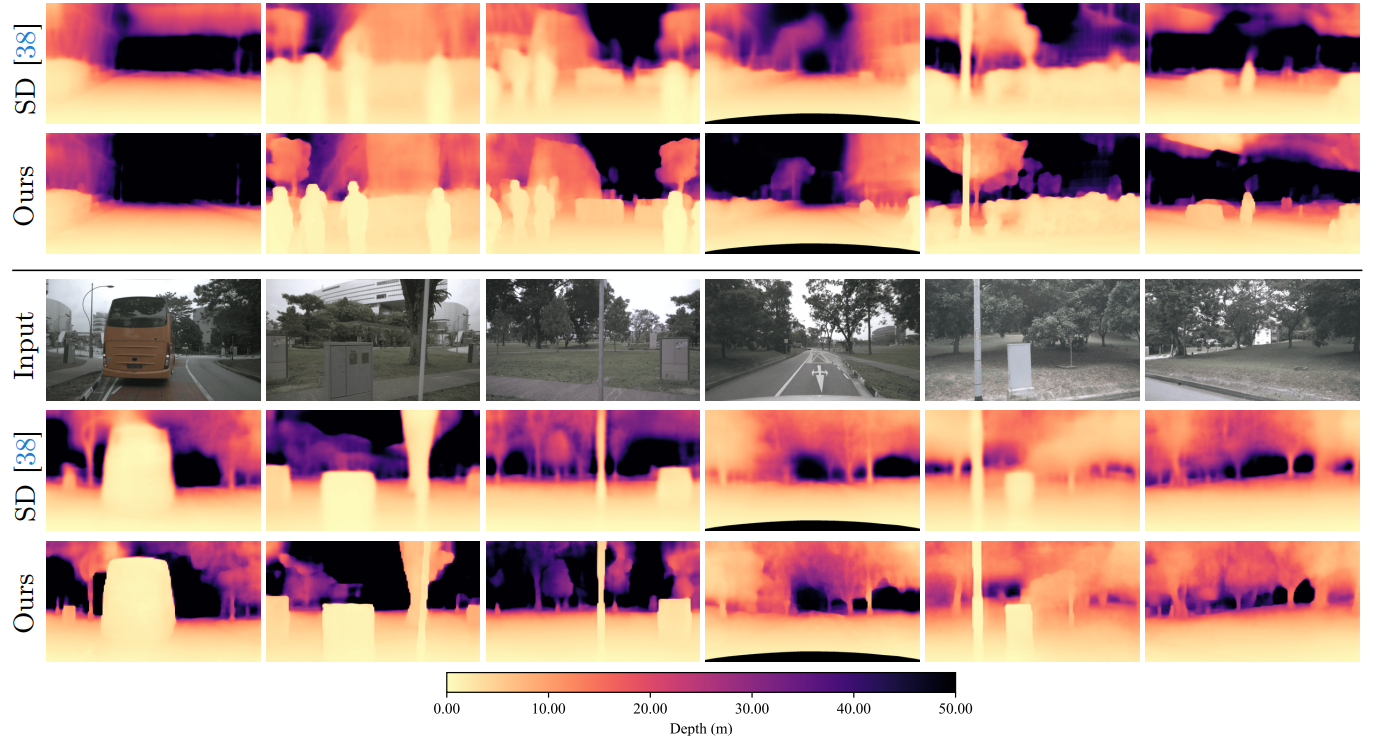
Scene understanding, occupancy prediction, autonomous driving
Generative Models
Diffusion models, video generation, scene generation